
Il y a quelques années, la définition d’un contenu optimisé pour le SEO se comptait en nombre de mots, en densité de mot clé et en balisage de titres. Ca c’était le bon vieux temps. Désormais, un contenu optimisé l’est de part son intégration au sein du site (notion de silo) mais aussi de par les informations qu’il contient (Knowledge Graph) et la façon dont il est rédigé (TF-IDF).
Tout ça a de quoi complexifier la rédaction web… Pourtant, derrière ces noms complexes se cachent des réalités très positives pour les internautes et au final peu de contraintes si la qualité est au centre de nos préoccupations. Voyons ensemble ces différents concepts et comment ils s’appliquent aux sites concrètement.
Le Knowledge Graph pour les nuls
En 2012, Google annonce officiellement la publication du Knowledge Graph dans son algorithme. L’aspect visuel de ce dernier est alors très largement commenté : lorsque vous posez une question à Google, il vous répond !
Si vous lui demandez quelle est la capitale de la France, il vous répondra « Paris » sans que vous ayez besoin d’aller cliquer sur un résultat de son index.
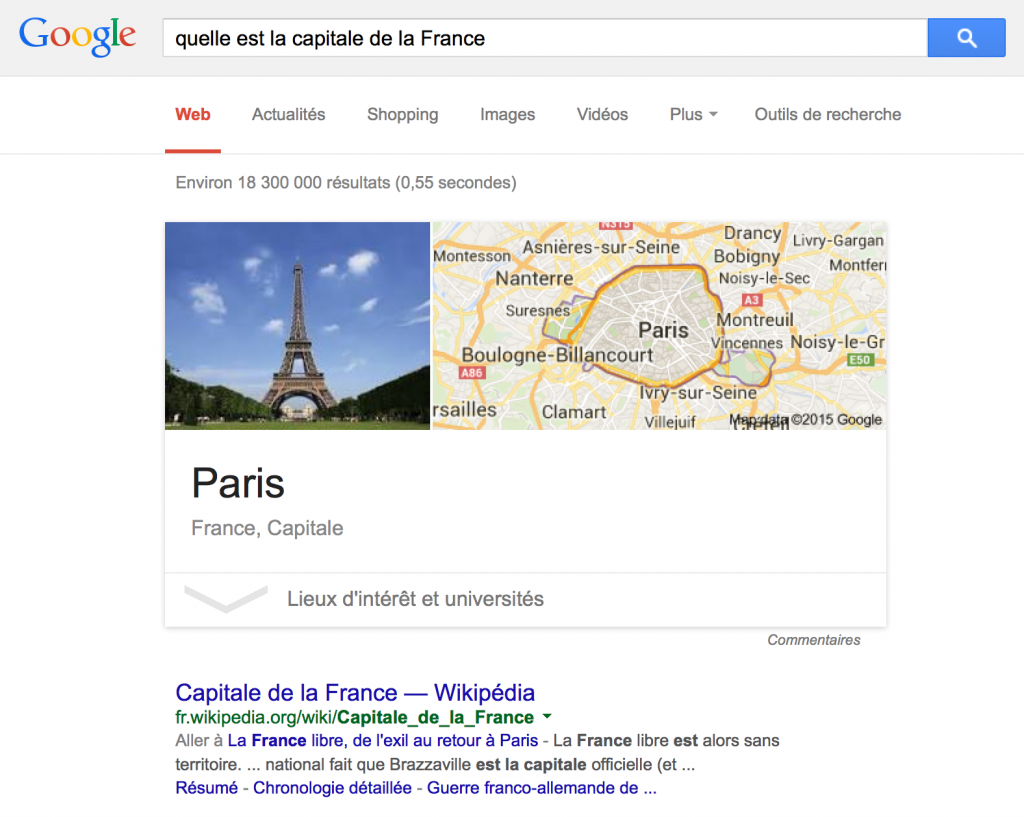
Mais derrière le Knowledge Graph, c’est toute la rédaction web qui est touchée. En effet, autrefois lorsque Google analysait un texte, il ne le comprenait pas. Il savait déterminer la thématique et le sujet d’un contenu certes, mais son intelligence s’arrêtait là. Désormais, à travers le Knowledge Graph, Google est capable de déchiffrer le contenu des textes.
Si vous écrivez sur Paris, il saura que Paris est la capitale de la France, qu’elle est traversée par la Seine et que c’est la principale destination touristique du monde.
Ainsi, parler de la Seine ou du tourisme sera bien perçu par l’algorithme du moteur si votre texte parle de Paris car très pertinent vis-à-vis du sujet évoqué.
Le côté négatif comme le souligne Sylvain du blog axe-net dans son article « Google : vers un algorithme sans backlinks », c’est la transposition de ces données qui peut se retourner contre les auteurs :
« Selon ce procédé, en disant ici que la bataille de Marignan a eu lieu en 1516, je grille cet article, car ce fait est inexact. Je décrédibilise mon contenu aux yeux de Google avec cette information erronée. Mais en disant que le premier anniversaire de la bataille de Marignan a eu lieu en 1516, je peux sans doute rattraper le coup, si la notion d’anniversaire est incluse dans l’algo. Bref, pas simple on le voit avec ce petit exemple basique. »
Pour aller plus loin : la notion de TF-IDF
Google comprend désormais les mots et les sujets évoqués ont donc une influence directe sur la qualité de ces derniers. Il existe une deuxième notion : la notion de TF IDF qui elle s’attaque aux mots même et notamment à leur rareté.
En effet, un des critères qu’utilise Google pour différencier deux articles de blogs plus ou moins similaire sera la qualité d’écriture. Pour juger cette dernière, il va regarder les mots employés par chacun des auteurs. Si l’un des auteurs aura tendance à utiliser des mots moins communs que le deuxième, tout en évoquant des thématiques liées et pertinentes à ses yeux, alors c’est ce dernier qui sera privilégié par le moteur.
Si j’écris un texte sur le basket-ball, je sais que 99% des articles sur le sujet contiennent le mot « ballon » : il est donc normal et nécessaire que mon article le possède également. Maintenant, si j’utilise des mots plus rares ou plus techniques comme « arbitres » ou « alley oop », seuls 5% des textes utiliseront ces derniers.
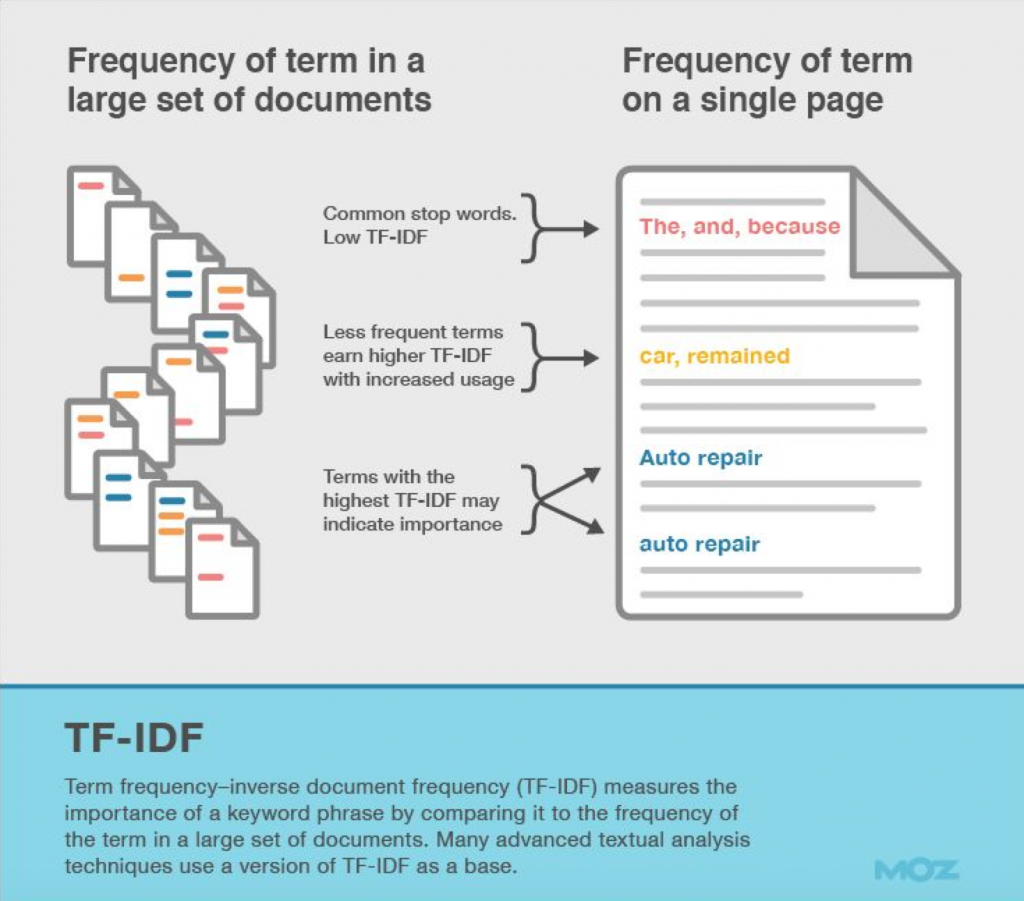
Ainsi, ces mots rares seront un élément permettant à Google de juger mon texte comme qualitatif, du moins un peu plus que ceux de mes concurrents.
A souligner le fait que la notion de TF-IDF n’est qu’un petit élément pour juger la pertinence et la qualité d’un texte, et n’est en rien auto-suffisante pour démontrer à Google la qualité d’un contenu.
Et pour finir, l’intégration en silo
L’ultime donnée permettant à Google de juger la qualité d’un texte (ou du moins de mieux le comprendre), c’est cette fameuse notion de silo.
Autrefois, le plus important pour un site c’était que Google puisse accéder à une page en suivant un ou plusieurs liens internes. Google jugeait ensuite de la pertinence des pages une par une sans nécessairement intégrer de données externes.

De nos jours, la façon dont Google accède à la page et donc la place de la page au sein du site a une influence directe sur ses performances potentielles.
Si vous publiez une page de contenu sur la nourriture pour chat et que cette page est isolée, elle n’aura aucun avantage particulier. Maintenant si vous la publiez au milieu d’autres pages sur la thématique des chats, au sein d’une catégorie de votre site qui ne traite que de chat, alors la pertinence de cette page sera tout autre et le seul fait qu’elle soit intégrée ici, avant même d’en lire le contenu sera un avantage concurrentiel aux yeux de Google.



La notion de silo c’est donc la classification de l’information au sein d’un site, c’est faire en sorte de découper un site en petites tranches logiques et pertinentes pour l’internautes de telles manières à ce qu’un texte qui parle de chat, soit lié avec les autres contenus qui parlent ou qui touchent aux chats.

Si vous lisez l’anglais, cet article très complet (qui est également la source des images ci-dessus) évoquera bien plus en détail la notion de silo et les méthodes pour l’intégrer à votre site.
Sans oublier l’essentiel
Je vous épargne le paragraphe disant qu’il faut penser aux internautes avant tout mais ces nouvelles notions ne doivent pas faire oublier les anciennes bonnes pratiques telles qu’une longueur minimale (discutable) et l’organisation du contenu (structurellement et en termes de balisage titres).
On peut également souligner l’avènement de la densité pondérée qui a définitivement enterré la densité brute qui consistait à répéter un mot clé le plus de fois possible pour faire comprendre à Google que c’était justement la requête que l’on ciblait.
Cette répétition est désormais bien plus subtile puisqu’il est avéré que deux éléments au sein d’une même page n’auront pas la même valeur : la balise titre et le footer pour prendre un exemple extrême auront chacun une importance relative très différente et intégrer le mot clé dans la balise titre aura bien plus de valeur que de l’intégrer dans le footer.
Ainsi, la répétition du mot clé dans les zones importante d’une page (balise titre, h1, quelques paragraphes clés) aura le même effet, si ce n’est bien mieux, que de se cantonner à une densité brute, très polluante pour la lecture et très à-même de vous apporter des ennuis auprès de Google.
Vous apprécierez peut-être également:
- Le nombre de pages idéal en SEO
- L’obfuscation, meilleure amie du SEO moderne ?
- Un contenu optimisé SEO c’est quoi ?
- Les 4 plus grosses pertes de temps en matière de SEO
- La densité de mot clé pour les nuls
Merci pour le billet. Je ne connaissais pas très bien la notion de TF-IDF. Pour écrire un article plus valorisant qu’un autre, il faudrait donc utiliser des termes plus rares dans la même thématique pour faire la différence et se démarquer auprès de Google ? C’est du moins ce que je retiens du TF-IDF.
Enfin, je tombe sur un article qui tente réellement de faire progresser ses lecteurs, merci. Par contre vous pourriez allez plus en détail en donnant des exemples. Notamment pour le knowledge graph où vous auriez pu expliquer comment en faire partie.
Bonne soirée
Amaury
Attention aux raccourcis, car si TF-IDF était aussi simple il suffirait de copier le dictionnaire des synonymes dans son article pour ranker comme un fou. Or non seulement c’est plus compliqué que cela (rappelez-vous, l’algo de Google comporte plus de 200 facteurs, c’est pas moi qui le dit c’est la webspam team) et d’autant plus que les filtres sortent aujourd’hui régulièrement et pénalisent des sites au fil de l’eau.
Il est urgent amha de laisser tomber tous ces conseils plus ou moins scientifiques, car c’est du blabla que Google ne mange pas : un site suroptimisé est flagrant comme le nez au milieu de la figure pour GG. Le SEO aujourd’hui, c’est de la désoptimisation : on évite les facteurs bloquants mais on fait rien d’autre que s’intéresser à ses contenus intéressants et signifiants pour les humains, pas les crawlers. Eux, ils s’adaptent. Depuis les débuts du web.
Salut
TF*idf permet effectivement d’identifier les termes peu fréquemment utilisés daans le langage courant et qui son présent dans un document.
Google semble surtout l’utiliser pour valider que votre texte correspond a la norme de ce qui se dit sur un sujet.
Si votre contenu est trop différent des autres articles traitant d’un sujet, google risque de ne pas trouver cela pertinent.
Il faut croiser la notion de TF*idf avec le cosinus de salton
super article. comme stéphane, Je comprenais pas tout a fait la notion de tf idf, c’est plus clair !
Tout à fait, l’intégration en silo c’est le nouveau défit pour les rédacteurs web qui vont devoir à présent être en mesure de proposer une cohérence thématique entre les différents articles destinés à un même site. Ceci dit, quand on se penche sur le sujet en profondeur, couplée à la qualité du contenu qui apporte une valeur ajoutée en terme d’information, c’est une aubaine pas seulement pour les algorithmes de Google mais aussi pour l’internaute qui prendra plus de plaisir à rester sur un site et donc cultivera sans surprise un intérêt particulier pour une marque ou pour une autre en fonction de ce qu’elle propose sur son site web en terme informatif.